How to scale: The 3-Laws of Process Building

Scalable Processes
Humans are creatures of patterns and repetition. In fact, we see meaning in patterns even when there isn’t any. There’s actually a name for the tendency to see patterns in random objects or occurrences: pareidolia.
Pareidolia is something simple to understand. It’s the act of seeing a face when we look at a power outlet, animals on cloud shapes, or a religious figure on a slice of bread. We’re not actively trying to find those shapes. Our brain automatically transforms those odd but familiar shapes into things we recognize.
The reason for such a quirky mechanism is simply that it’s more efficient. We see the pattern before we see the individual shapes or attributes. It’s part of the reason why you can recognize people so fast even though you can barely remember their eye color. It’s the same thing as when we read: a proficient reader will see the words before the letters, and even grasp the meaning of full sentences without acknowledging individual words.
The problem of this, of course, lies in the loss of quality. Everyone can draw a smiley face with two dots and a curved line. However, it takes years of practice and study of the individual features of a face for an artist to draw a realistic portrait.
For example, let’s imagine an aspiring artist named Dave.
Dave’s dream was to draw portraits. To achieve this, he decides to start copying pictures and photos of his family. Soon, he hits his first plateau: he can make a near perfect replica of a picture, but he cannot draw someone from imagination. Whenever he tries to, it comes out wrong. The individual pieces are there, but they feel off.
Dave then decides to study individual features: lips, noses and eyes. His drawings noticeably improve, but they still look odd, somehow. But then, he has an epiphany: he understands that drawing is not only about the individual features themselves, but there’s something else that dictates how good the final result will be: perspective. Or rather, how each individual piece is related to each other.
It’s only when Dave masters this last concept that he can truly create good art from scratch.
When we talk about processes, something similar occurs.
Every company has processes and, at first, it’s normal for those processes to be the equivalent of a smiley. They’re an impression of what the process should be, created by people who don’t know quite enough yet about the individual parts to successfully create a good framework.
The natural progression for the company is to try to improve this initial process (which likely arose organically) by implementing an existing, generic framework (such as Agile, or Zero-Based Budgeting). This greatly improves the efficiency of the process, but it’s still not the most efficient solution for that specific company. Why? Because generic processes can never account for individual differences.
The final leap to full efficiency is only achieved with a tailor-made process that takes into account every individual feature/problem of the company and is designed around those.
As you can see, this is very similar to Dave’s journey as an artist.
Those similarities can be broken into steps and define the four stages to truly empowered, autonomous teams:
Aspiration → Replication → Understanding → Creation
Aspiration: in this stage, we have a raw understanding of what we’re trying to achieve. This is the stage of pareidolia, where we understand and implement the patterns despite the flaws in the individual features.
Replication: in this stage, we acknowledge the process is lacking, but don’t know how to improve. We try to copy the Greats, with varying degrees of success.
Understanding: in this stage, we know copying will only get us so far. Here, we study the why’s and how’s, and even manage to change existing frameworks to our needs.
Creation: in this stage, we finally understand enough to create specific solutions to our problems. It’s here that we develop our own art style, the one that fits our goals.
The idea of jestor’s methodology is to teach you how to go from mere Pareidolia to Process.
Data as Building Blocks
Processes are unique, but they’re usually built of the same thing: data.
Think of reality itself. You and your smartphone are very different things, but can ultimately be broken down into smaller pieces until you get the same building blocks. Matter becomes molecules, which becomes atoms, which become quarks. The different arrangement and purpose of those building blocks are what make them feel different, but they are fundamentally the same. How they’re related to each other is what brings meaning to them.
Processes are the same. No matter the purpose, everything comes down to organized data. If you find that strange, let’s imagine a customer support pipeline for a moment and delve into the very first step: a customer opening a support ticket.
At first glance, the client and their ticket may seem like two very distinct things. But actually, they are just groups of repeating data.
A client may be characterized by a name, email address and subscription plan.
A ticket may be characterized by an ID, the problem and the stages until resolution.
As such, we can write them in the following format:
[clients: name, email, plan]
[tickets: id, problem, status]
As you can see, even though they behave differently and have different roles in the process, they both can be written as groups of information. We call those building blocks.
Building blocks have a very specific format: they always have a label and what we call boxes. Boxes are things that can have a value inside. In the ticket example, ID is a box: it could be #0001, #0002 and so on.
Do notice that we couldn’t have something like:
[status: new, on course, done]
Why? Because new, on course, and done are not boxes. They are the values themselves.
The secret to process building is recognizing those building blocks and how they connect to each other. Don’t worry, we’ll get back to that (but you can already try to guess how tickets and clients are related to each other.)
For further understanding of how Building Blocks work, check out our class about it at Class One – Building Blocks – Jestor
The Three Laws of Process Building
Sci-fi enthusiasts should be familiar with the concept of the Three Laws. For the uninitiated, they’re a set of three rules created by author Isaac Asimov, and they dictate robots’ behavior: no matter what a robot was ordered to do or did by its own will, it could not break those three rules.
The rules are:
First Law: a robot may not injure a human being or, through inaction, allow a human being to come to harm.
Second Law: a robot must obey the orders given it by human beings except where such orders would conflict with the First Law.
Third Law: a robot must protect its own existence as long as such protection does not conflict with the First or Second Law.
Asimov’s robot stories usually revolved around the three rules. Or rather, the natural conclusion to following those rules in many different situations.
Tip: We strongly recommend that you read ‘I, Robot.’ It won’t really be needed for this course, but it’s a damn good book.
Just as Asimov’s rules cannot be broken, we find that there are three rules to process building that should always be followed, or chaos ensues. They are simple laws, but they’re usually ignored by novice process builders. That’s because they’re not natural. You’ll see that they directly contradict our instincts when it comes to organizing our thoughts. But, even if they feel arbitrary and restricting, we urge you to follow them. They’ll keep you focused on the correct path and, in many ways, you’ll find those restrictions are in fact quite liberating.
First Law: a builder must think linear, but build parallel
Processes can usually be written in chronological order. Take a close look at the example below:
Cold Email → Meeting → Proposal → Negotiation → Closure
As far as sales processes go, this one is quite straightforward. Sure, it could be expanded to contain a series of different steps, but right now, let’s focus on how simple it is. It should be really easy to transform this into a process, right?
As a chronological process (i.e. something that moves in steps), we might decide that the best view for this is a kanban, and the stages of this kanban are the steps of the process. Following this rationale, we might end up with something like this:
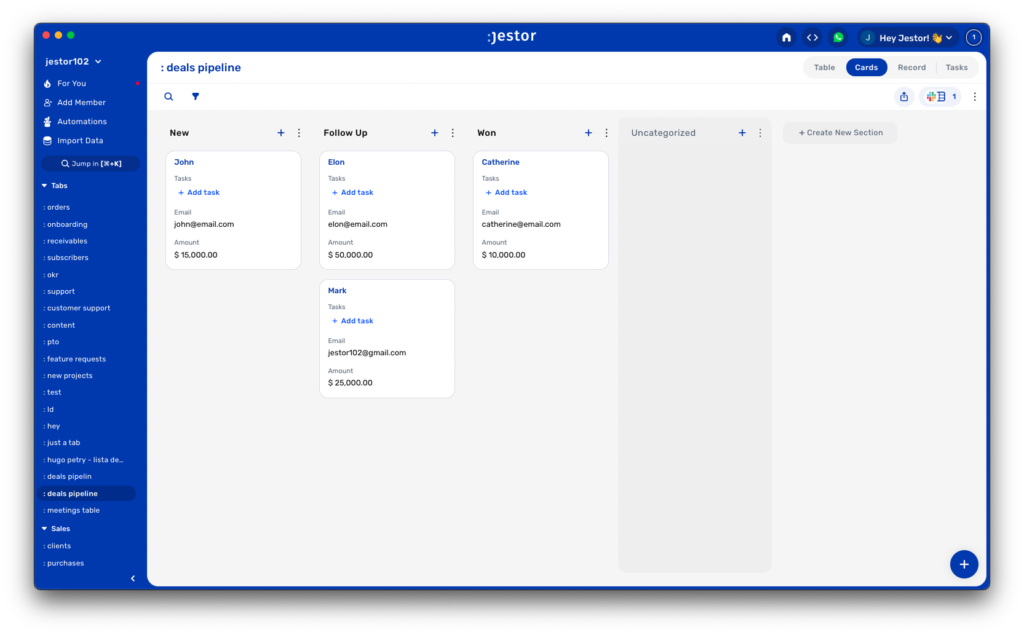
Wow! It even looks like a regular CRM. We must be on the right track, right?
Of course, only having the name of a client moving along a pipeline is not particularly great. We need more data for this to be truly useful for us. As an exercise, we can think about information that would be useful for us:
- Client’s email and phone number;
- Deal Value;
- Meeting Date;
- Follow up Date;
- Proposal .pdf.
Our first instinct is to build this directly onto the kanban card. If we tried to write this as a building block, we’d get something like:
[deals: id, client name, client email, client phone, value, meeting date, follow up date, proposal, status]
For a while, this structure might even work. But, as we further used this simple CRM, we would see some problems naturally arise:
- The billing team needs the client’s info, but not necessarily the deal’s other info;
- We might have multiple proposals as negotiation goes on and we’d like to keep all of them stored somewhere;
- We may need multiple meetings before closing the deal;
- Sales team easily loses track of follow ups and client history.
We could give the billing team access to the sales pipeline and create a new field of data for every additional follow up and meeting date. If we did that, our building block would look something like this:
[deals: id, client name, client email, client phone, value, proposal, status, meeting date 1, meeting date 2, meeting date 3 . . .]
Yuck. This is going to get messy and confusing really quick. It’s the equivalent of having a spreadsheet with 30+ columns when most of them aren’t really necessary. The problem here is that though the process is linear, the parts themselves aren’t. Let’s try to break this mega building block down into smaller pieces.
We can do this by asking two questions:
- Will this information be used elsewhere? (or rather: is it independent?
- Will there be multiple, repeatable rows for the same process?
To make this more practical, let’s start with the Deal itself:
[deals: id, client name, client email, client phone, value, meeting date, follow up date, proposal, status]
There are three boxes that are directly related to client info: name, email and phone.
[deals: id, client name, client email, client phone, value, meeting date, follow up date, proposal, status]
The first question we have to ask is: could this information be used elsewhere? And the answer is yes. The billing team will need the client information, as well as the customer success team, for example. This is a big indicator that client info should not be on the boxes of a deal, but rather be a building block itself, like:
[clients: client name, client email, client phone]
Next we have the deal value. In this case, you should only have one and it’s a meaningless number outside of the context of the deal itself, so this indicates value is nothing but a box of the deal.
Then we get to “meeting date.” It’s a type of information that probably won’t be used by itself, but as we’ve said before, we could probably have many meetings for one deal alone. This is a good indication that Meetings should be a building block. We can even expand on it to contain more than a date:
[meetings: date, type, notes]
Similarly, we can have many follow ups attached to the same deal. Not only follow ups: maybe there are other important tasks, such as sending proposals or elaborating quotes. Let’s make a generic building block for that:
[tasks: deadline, type, owner, status]
Proposals should follow a similar structure:
[proposals: value, attachment]
Finally, the deal should only have one current status, and as it’s information that won’t make sense on its own, it should only be a box of the “deals” building block.
The final product will look something like this:

You may be wondering now where the client information is. Well, we’ve decided that “clients” should be building blocks by themselves, right? And actually, a client can have more than one deal during its lifetime. So the whole structure should actually look something like this:

With this structure, we’re basically making an assessment that:
- A client may have more than one deal;
- A deal may have more than one meeting, task, or proposal.
This ensures that data is organized in the most scalable way possible. It won’t matter if a deal has one task and the other one has a thousand: the structure will always look the same and there’ll be no need to change it.
Alright, so how do we transform the image above in a scalable system? You can see every building block points to another block, except for “client”. So when you build a data block, you should keep this relation in mind: points to, or connects to. We’ll indicate this with an upward arrow (↑).
So, we have:
[clients: client name, client email, client phone]
And then:
[deals: id, value, status, ↑client]
And the last row is:
[meetings: date, type, notes, ↑deal]
[tasks: deadline, type, owner, status, ↑deal]
[proposals: value, attachment, ↑deal]
This is not a natural way of thinking about processes. We’re used to linear building, or what we like to call workspace logic.
Workspace logic dictates that everything related to a process should be built inside the same place and contain all the information. It seems sensible, but it isn’t the best way to build scalable processes. Modular processes, based on building blocks, help you organize the information, layer it according to relevance, and make it accessible anywhere without having processes interfering with each other.
If I want to see client info, I don’t really need to see specific deals, but I should have access to them.
If I want to see a specific deal, I don’t really need to see all the meetings and tasks and proposals, but I should have access to them.
So the natural conclusion to workspace logic will get you something like this:
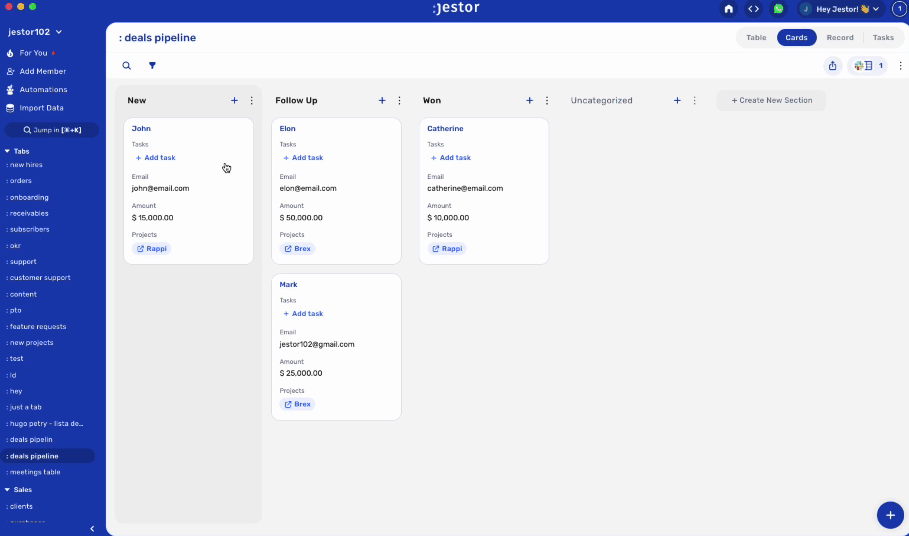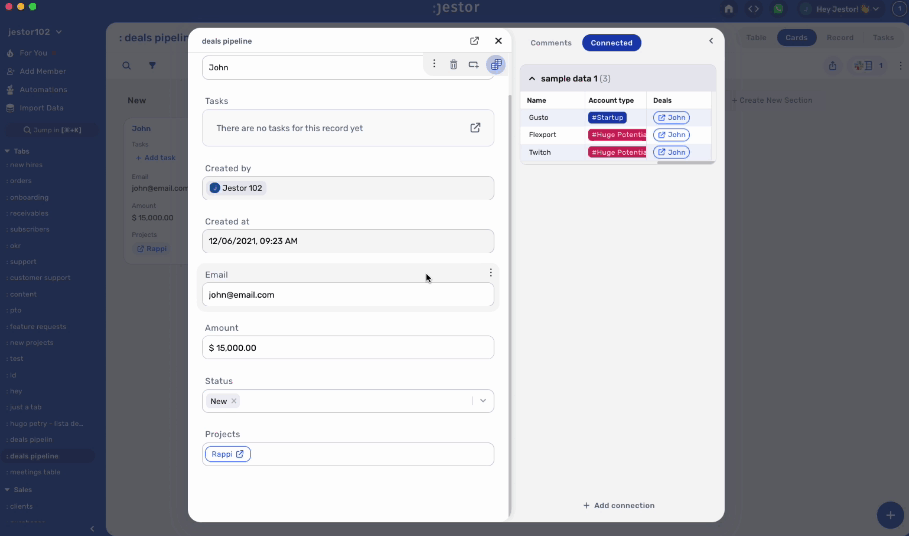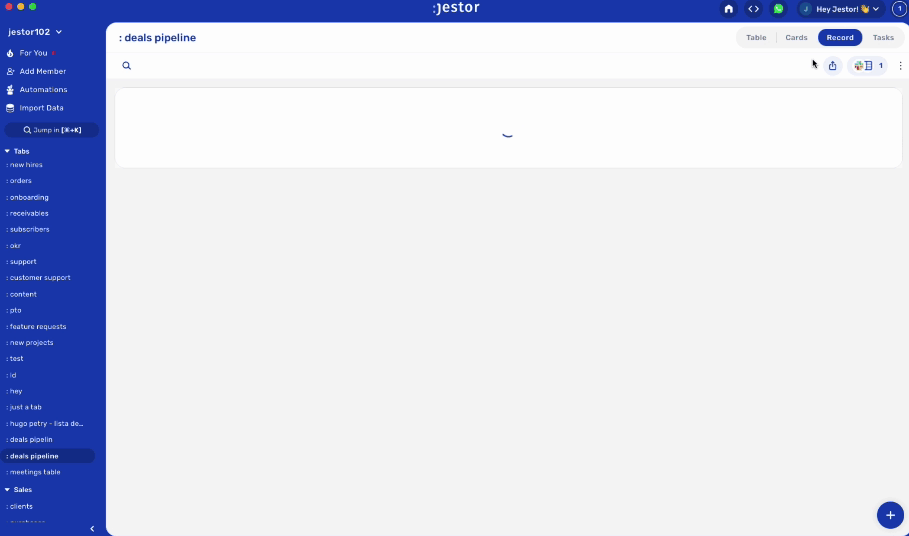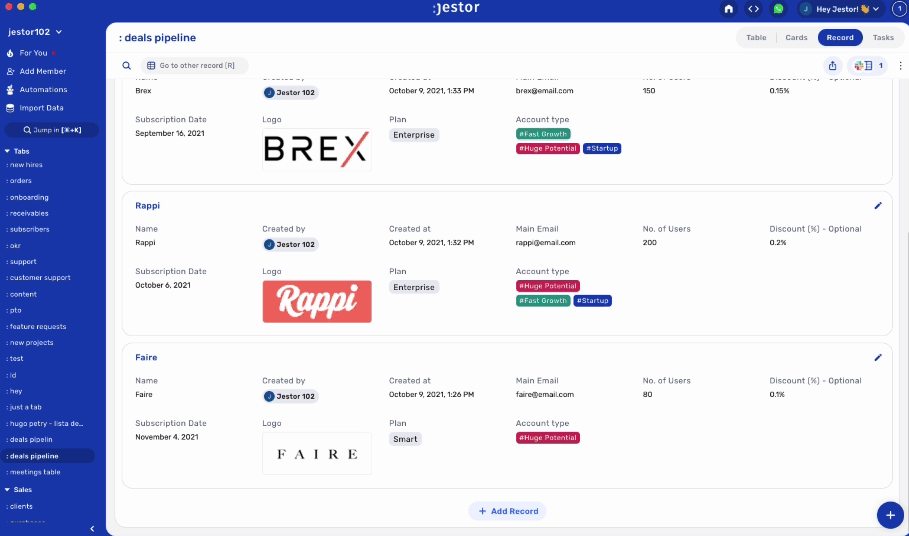
Which is… serviceable at best. It may even get the job done, but it’s very confusing. There’s too much unnecessary information visible at the same time, and if I have to get any individual information (such as the client’s phone number), it’s always attached to a specific deal, even though it could exist on its own.
Parallel building, however, will get you something like this:
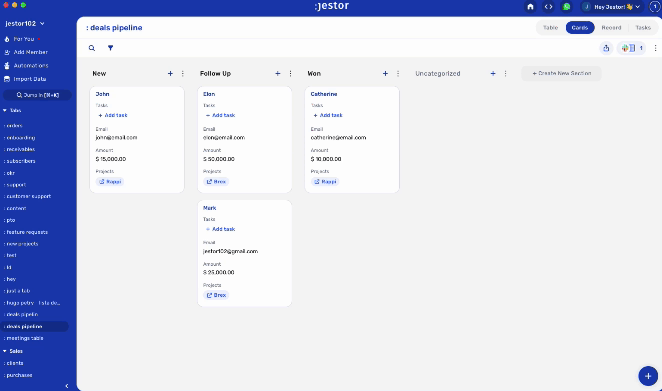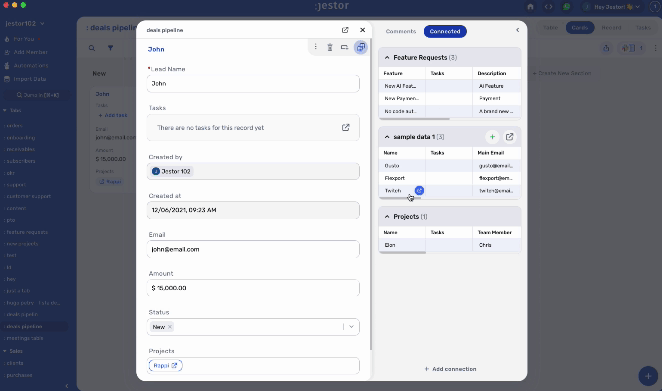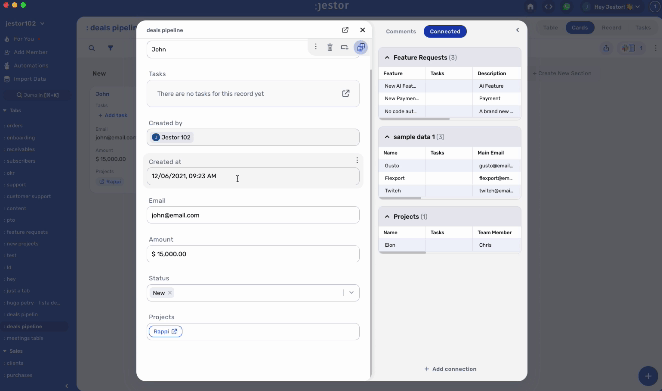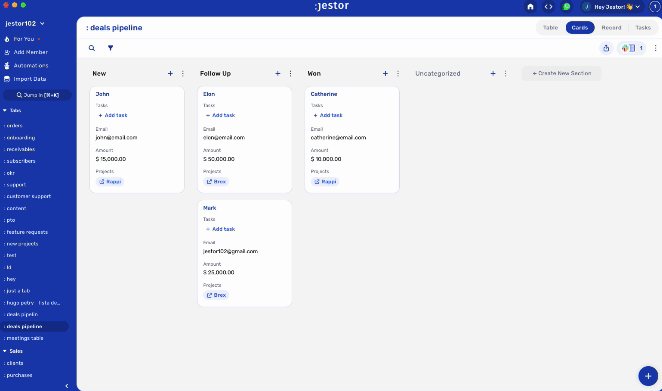
You’ll note that every information is easily accessible, but prioritized and organized. In fact, we have a lot more data fields in the second example, but the process itself is less cluttered. If I want to see all the proposals, they are neatly organized on a dedicated table that I can filter and easily search to find what I need.
For further understanding of how Building Blocks work, check out our class about it at Class Two – The First Law – Jestor
Second Law: a builder must use outcome oriented design
The second law sounds obvious at first, but it’s something novice process builders will unconsciously fail at: a good process shouldn’t collect garbage data, nor will it go out of its way to preserve bad habits.
There’s a famous adage in writing that urges authors to “kill their darlings.” It’s not as dramatic as it sounds: it merely states that no matter how much you love a character, scene or plot device, you should never let it get in the way of the story.
Processes work in a similar fashion.
It’s not uncommon for processes to have “legacy” parts, bits that exist not because they’re useful, but because they somehow managed to slither themselves into the first iteration of the process and no one ever really bothered to yank them out.
The problem here is that organic, pareidolic processes always bulk up. The natural way of solving problems is keeping what works and adding new parts. As a result, processes tend to grow from meek frameworks to complex juggernauts, and suddenly you find yourself with a car that has three engines, seven wheels, eleven rear view mirrors, and no one really knows why. Those legacy parts just keep piling up, bogging the process down.
Usually, those parts exist for one of the following reasons:
- Someone really liked the idea despite no real need for them. We’ve all been there. For some reason, the Sales team really needs to know the prospect’s astrological sign, despite never having once used that information for anything at all.
- Those parts were once necessary, but not anymore. A classic example is printing a document and asking for a manager’s signature despite every other part of the process being strictly digital, or even pestering a customer for a second phone number because the previous ERP required it for registration.
- They’re part of a generic framework. This is the equivalent of false common sense. I mean, every CRM must have “lead temperature,” right? Not really, unless you plan to act on it.
Now, the thing about legacy parts is that it’s really hard to justify dumping it. I mean, it was always there, so it must have a purpose, right? When building processes, we have a tendency to look at all the Input information we can/do collect and try to get the best possible Outcome with it.
This mindset, of course, preps you to build shoddy processes. It’s the equivalent of looking at every single thing in your fridge and wondering how to make a fruit salad out of it, even if all you have is steak. Good processes, however, start backwards: you must first define the desired outcomes, and only then figure out the necessary input and steps.
As an exercise, let’s imagine a simplified purchasing process. We’ll go through the legacy process and then go through the Second Law to see how we can improve it.
The Curious Case of Butterscotch Bottles
Butterscotch Bottles is in the business of edible butterscotch flavored bottles. As part of their rigorous manufacturing process, they buy only the finest ingredients from the most reliable suppliers. Still, about 5% of the ingredients they buy still aren’t up to their standards, so they decided to implement a process of Quality Control for their purchases.
Eventually, a process emerges organically:
- Purchaser issues an order for ingredients;
- Ingredients arrive at the warehouse;
- Inspector prints form with every ordered item;
- Inspector goes through each item, looking for defects and blemishes;
- Inspector fills form with defective items;
- Remaining items are stored for future use. Defective items are thrown out and the supplier is contacted for replacement.
The form on step (5) might look something like this:
Inspection Form
Order: #0376
- Sugar – 100kg – OK
- Butter – 20kg – Partially OK
- Salt – 50kg – Partially OK
Notes:
- 1kg of butter NOT OK;
- 3kg of salt NOT OK.
Now, this might work for a while, but as time goes on the company might decide that this process should be digital, as the current method of printing forms is generating too much garbage and is hard to organize.
Our first version of the digitized process will be a legacy focused solution: that is, keeping the process as is.
Legacy Solution
If we think of this process in building blocks, we’ll get something like this:

- You have a supplier who has an order (or more).
- You have an order that:
- Points to a supplier;
- Can have many items;
- Can have an inspection form.
- You have items that:
- Point to an order.
- You have an inspection form that:
- Points to an order;
- Can have many defective items.
- You defective items that:
- Point to a form.
When thinking about the labels and boxes, you should get something like:
[suppliers: name, address, email, phone number]
[orders: id, amount, status, ↑supplier]
[items: name, quantity, ↑order]
[form: ↑order]
[defective items: name, quantity, ↑form]
The solution will look something like this:
It makes sense, right? However, there are still legacy parts in the process that have no real need to be there. Can you spot them?
Outcome Oriented Solution
If we think about the desired outcome of the process, we might phrase the problem as something like this:
“I want my supplier to replace defective items.”
So the outcome of my process is the number of defective items, so I need someone to inspect the items. For someone to inspect the items, the company must have placed an order from a supplier. Linearly, it’ll look something like this:
Place Order → Wait for Arrival → Inspect Items
In those steps, I know:
- “Number of Defective Items” is a necessary part of the process, because that’s what the supplier will need to replace.
- “Supplier”, “Order” and “Items” are necessary parts of the process because they’re inherent to the purchase itself.
The form, however, is a legacy part. The only reason it’s there is because the process was previously done by hand on a printed sheet of paper. It’s an artifact that’s only really necessary because of limitations imposed by software/resources.
Also, when you think about the form, not only it’s a legacy block itself, it creates legacy data: why should “defective items” be building blocks, if they only mirror the purchased items with a different quantity?
We could cut the form altogether, and change the purchased items from:
[items: name, quantity, ↑order]
To something like:
[items: name, purchased quantity, defective quantity, ↑order]
By merging “defective items” into the order’s “items” and cutting out the form, our process will look something like this:

Now, when the order arrives, the Inspector only needs to fill out the Defective Quantity of an item when necessary, then change the order status to Inspected.
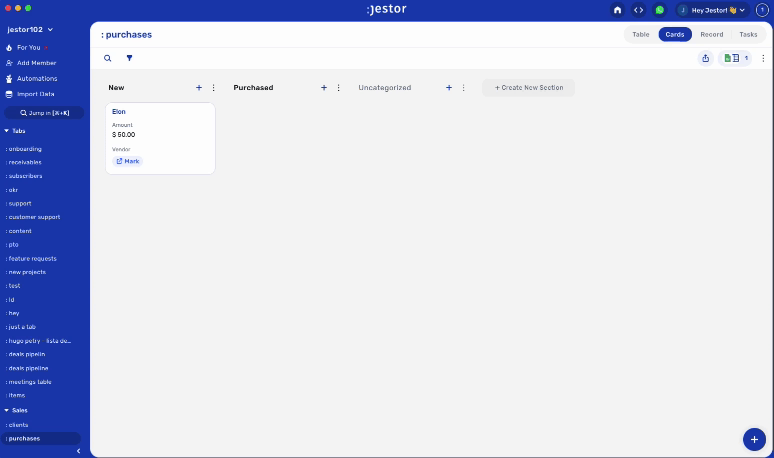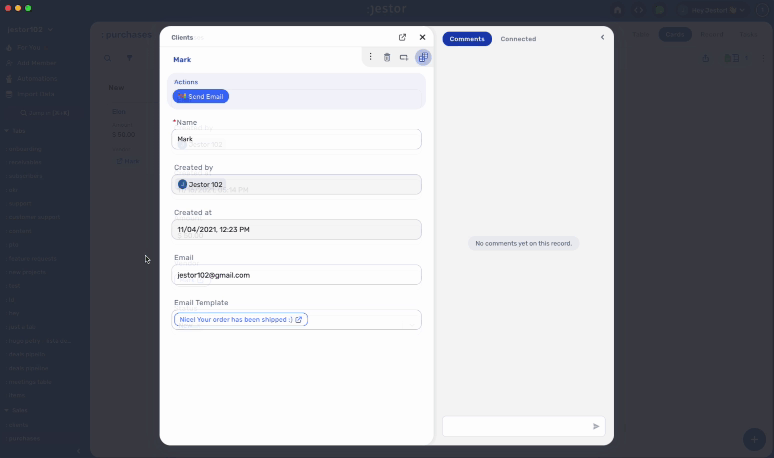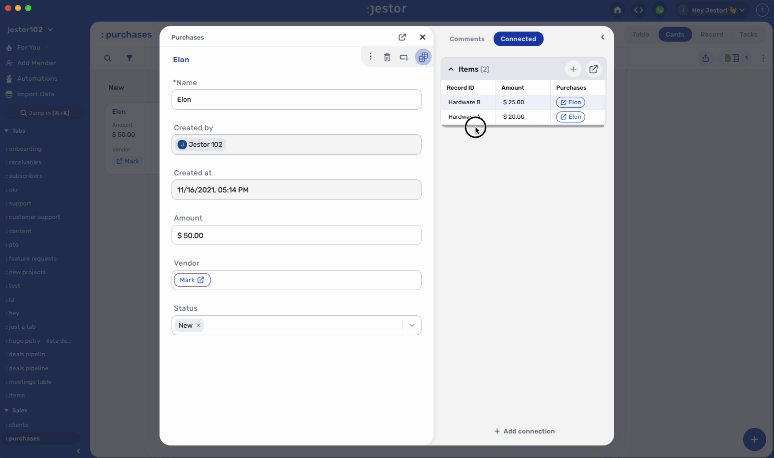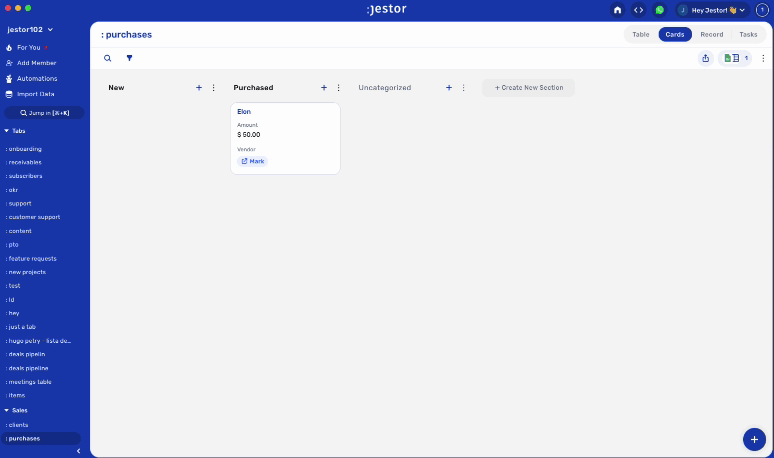
This process is leaner, has fewer steps and is easier to organize. Should I open the order, the number of defective items is only one layer of data below instead of two, and the relationship between purchased items and defective items is much clearer.
Using Outcome Oriented Design, you can understand what parts of the process are actually necessary, and cut the legacy parts accordingly.
For further understanding of how Building Blocks work, check out our class about it at Class Three – The Second Law – Jestor
Third Law: a builder must focus on the minimum viable process
The thing about companies is that they’re complex entities, with many goals and necessities. As a result, they’ll have many processes going on at the same time.
Sometimes, those processes will align themselves and look like they’re a single entity.
As an example, we can have the Marketing team creating ads to attract leads to the company’s website. A simplified view of this process will look something like this:

The input of this process is the definition of a strategy (discount for annual subscriptions, for example) and the output of this process is new leads coming to the site. They might tweak the strategy for different results, such as more leads, or better leads, but if this Marketing team existed in a vacuum, the blocks above are the only thing that matter for it’s daily routines.
Then we have the Sales team: their job is to contact the leads and convert them into paying customers. A simplified view of this process will look something like this:

You might have noticed that the outcome of the Marketing process is the input for the Sales process. So, when sketching the process you’re trying to build, you might be inclined to do something like this:

But then you remember that “paying customers” is the necessary input for the Billing team and the Customer Experience team, so you sketch out the next steps:

And at some point you realize that there’s a process to get in touch with lost deals after a while and try to convert them into paying customers too. The input is “Lost Deals”, which comes right from the middle of the Sales process…

As you can see, things are starting to get really complicated.
If we tried to transform the sketch above into a process, there are a number of things that could go wrong:
- Spill Over: by connecting processes into a mega process before building them individually, you increase the chances of creating the wrong building blocks. For example, you might build a single, complex kanban that contains the client’s info, as well as both the Sales and Customer Experience stages, making it harder/messier for both teams to operate the kanban, nevermind the headache it’d cause for the Billing department (the best solution, of course, would be to have two different kanbans that both point to the Lead/Client).
- Input Oriented Design: as the process grows bigger, it becomes increasingly difficult to think of the necessary outcomes and work backwards to find the necessary inputs. After all, the relationship between “Marketing Strategy” and “Send Invoice” is not immediately clear, at least not as clear as “Paying Customer” and “Send Invoice.” So, as a result, we tend to discard Outcome Oriented Design and build based on possible inputs.
You might notice that Spill Over is a consequence of not applying the First Law. In fact, it’s the exact opposite of it: Spill Over is nothing more than thinking parallel and building linear. Similarly, Input Oriented Design is the opposite of the Second Law.
In a way, the Third Law is a way of ensuring you don’t break the first two laws. As long as you focus on the minimum viable processes, you shouldn’t have a hard time creating the best building blocks and letting the desired outcomes guide your project.
So, if instead of thinking of a mega process I divide the sketch into many minimum viable processes, I’d get something like:
- Marketing;
- Sales;
- Billing;
- Customer Experience;
- Lost Deals Re-Engagement.
Those are way more manageable processes to build. They are shorter and self explanatory. And the thing is: as long as I remember to build parallel and create the right building blocks, I can start process building in any order I want.
I could, for example, start with Billing if it’s urgent, and only then build the Sales process. That’s because Billing could be a self contained process that starts with a manual list of “Paying Customers” and, as long as it has this input, it should run smoothly. Then, when I build the Sales process, I could feed its outcome to the Billing team just by connecting the correct building blocks.
Of course, there’s also a marvelous side effect of focusing on minimal viable processes: adaptability. Those modular processes can be expanded, swapped, shut down or rewritten without affecting the other processes. When aiming for scalability, the Third Law ensures a company can move fast with out breaking more things than necessary.
For further understanding of how Building Blocks work, check out our class about it at Class Four – The Third Law – Jestor
Process as storytelling
To end this guide, we urge you to think of yourself not only as a process builder, but as a storyteller. Your job is not only creating the best possible structure, but helping actors seamlessly navigate through it.
In writing, there’s a common advice when creating characters: a character should always want something, no matter how small. It could be overthrowing a corrupt government, but it could also be something as simple as buying a new bicycle. It doesn’t matter: what matters is that when a character wants something, every action they take is usually aimed at achieving their goal.
When you present someone to a process, they’ll follow the same rationale: if the Account Executive’s job is to close deals, every action they take will be something they feel brings them closer to closing a deal. This means:
- It should always be clear what they have to do now to advance them to the next step, or else their instinct will be to stay put rather than take action;
- Things that are not necessary for that goal will usually be skipped. This means if you want the Account Executive to collect the lead’s website but that’s not required for closing the deal, chances are they’ll never bother with it.
That’s why everything matters: labels, boxes, the order of the information, which information is required to move to the next step. Everything should be built with intent. At any point of the process, it should be clear how to move forward:
- Do you want to close the deal? Send the proposal;
- Do you want to create a blog post? Submit the first draft;
- Do you want to purchase an item? Get quotes from suppliers.
That’s why the Three Laws are important:
- By building parallel, you make sure data is always organized and easy to access in case someone needs it for a step;
- By using outcome oriented design, your steps will be optimized for achieving a goal, helping the end-user understand the way forward;
- By focusing on the minimum viable process, the structure is designed for the individual journey of each user, not more.
And then, when the structure itself is finally built, you can think of it as the equivalent of a rough first draft: it establishes the characters and makes clear what the purpose of the story is, but must be edited and improved until you get a good novel. On a first draft, novels usually have many points of friction: heavy blocks of exposition, unnecessary dialogue, stilted dialogues. They get in the way of the reader’s journey to see the character’s achieving their goals, and are cut during the editing phase.
On processes, friction usually comes in the way of unnecessary steps and repetitive tasks. If you’ve been following the Three Laws, you’ve already got rid of the unnecessary steps, but repetitive tasks can be eliminated by the way of automations.
Automations streamline the process and let people focus on moving forward, instead of being bogged down by repetition and manual work. It’s the final step towards a fully efficient process, one in which actors aren’t spending their time in bureaucracy, but rather making decisions.
A word of caution, of course, is to remember automations should serve the process, not the other way around. A process that ditches the Three Laws for an automation will usually make the team lose all the efficiency it gained by having something automated. In some cases, new processes will organically arise in order to circumvent the automation, because even pareidolic processes are better than nonsensical, bureaucratic processes.
As a process builder and storyteller, always remember that, if people don’t understand your story, they’ll make stories of their own.